Недавно возникла необходимость установить систему мониторинга
Nagios Core 4 на сервер под управлением
Linux Debian 6 (Squeeze). Здесь изложу свой опыт. В принципе, на Debian 7, Ubuntu, а также RHEL-ы (CentOS, Oracle Linux, Fedora) Nagios ставится походим образом. Необходимо лишь учитывать особенности путей на этих системах и наименования пакетов для установки.
Подробнее про Nagios, различие его редакций и т. д. можно прочитать на официальном сайте проекта.
Планируется установить следующие компоненты:
- Nagios Core,
- Nagios Plugins,
- NRPE,
- Nagios V-Shell (симпатичный фронт-энд для Nagios Core).
Установить можно как из пакетов, так и путём компиляции из исходников. В данной статье использован второй метод, т. к. он обеспечивает инсталляцию наиболее последней версии Nagios, а так же лучшую интеграцию компонентов между собой.
1. Установка зависимостей
apt-get install wget build-essential apache2 php5-gd libgd2-xpm libgd2-xpm-dev libapache2-mod-php5 php-apc libssl-dev
2. Создание пользователей и групп
useradd -m nagios
groupadd nagios
groupadd nagcmd
usermod -a -G nagcmd nagios
3. Скачивание необходимых архивов. На момет написания статьи последняя версия Nagios Core – 4.0.2, NRPE – 2.15
mkdir downloads
cd downloads
wget http://prdownloads.sourceforge.net/sourceforge/nagios/nagios-4.0.2.tar.gz
wget http://assets.nagios.com/downloads/nagiosplugins/nagios-plugins-master.tar.gz
wget http://assets.nagios.com/downloads/exchange/nagiosvshell/vshell.tar.gz
wget http://sourceforge.net/projects/nagios/files/nrpe-2.x/nrpe-2.15/nrpe-2.15.tar.gz
4. Распаковка архивов
tar zxvf nagios-4.0.2.tar.gz
tar zxvf nagios-plugins-master.tar.gz
tar -xzvf vshell.tar.gz
tar -xzvf nrpe-2.15.tar.gz
5. Компиляция и установка Nagios Core
cd nagios-4.0.2
./configure –with-nagios-group=nagios –with-command-group=nagcmd –with-mail=/usr/bin/sendmail
make all
make install
make install-init
make install-config
make install-commandmode
make install-webconf
cp -R contrib/eventhandlers/ /usr/local/nagios/libexec/
chown -R nagios:nagios /usr/local/nagios/libexec/eventhandlers
/usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
6. А здесь я столкнулся с такой проблемой, что скрипты запуска в 4-й версии написаны несовместимо с Debian 6. Поэтому, необходимо содержимое файла /etc/init.d/nagios заменить на следующее:
#!/bin/sh
### BEGIN INIT INFO
# Provides: nagios
# Required-Start: $remote_fs $syslog
# Required-Stop: $remote_fs $syslog
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: Start nagios daemon at boot time
# Description: Nagios 4.0.2 daemon
### END INIT INFO
#
# chkconfig: 345 99 01
# description: Nagios network monitor
#
# File : nagios
#
# Author : Jorge Sanchez Aymar (jsanchez@lanchile.cl)
#
# Description: Starts and stops the Nagios monitor
# used to provide network services status.
#
# Load any extra environment variables for Nagios and its plugins
if test -f /etc/sysconfig/nagios; then
. /etc/sysconfig/nagios
fi
status_nagios ()
{
if test -x $NagiosCGI/daemonchk.cgi; then
if $NagiosCGI/daemonchk.cgi -l $NagiosRunFile; then
return 0
else
return 1
fi
else
if ps -p $NagiosPID > /dev/null 2>&1; then
return 0
else
return 1
fi
fi
return 1
}
printstatus_nagios()
{
if status_nagios $1 $2; then
echo “nagios (pid $NagiosPID) is running…”
else echo “nagios is not running”
fi
}
killproc_nagios ()
{
kill $2 $NagiosPID
}
pid_nagios ()
{
if test ! -f $NagiosRunFile; then
echo “No lock file found in $NagiosRunFile”
exit 1
fi
NagiosPID=`head -n 1 $NagiosRunFile`
}
# Source function library
# Solaris doesn’t have an rc.d directory, so do a test first
if [ -f /etc/rc.d/init.d/functions ]; then
. /etc/rc.d/init.d/functions
elif [ -f /etc/init.d/functions ]; then
. /etc/init.d/functions
fi
prefix=/usr/local/nagios
exec_prefix=${prefix}
NagiosBin=${exec_prefix}/bin/nagios
NagiosCfgFile=${prefix}/etc/nagios.cfg
NagiosStatusFile=${prefix}/var/status.dat
NagiosRetentionFile=${prefix}/var/retention.dat
NagiosCommandFile=${prefix}/var/rw/nagios.cmd
NagiosVarDir=${prefix}/var
NagiosRunFile=${prefix}/var/nagios.lock
NagiosLockDir=/var/lock/subsys
NagiosLockFile=nagios
NagiosCGIDir=${exec_prefix}/sbin
NagiosUser=nagios
NagiosGroup=nagios
# Check that nagios exists.
if [ ! -f $NagiosBin ]; then
echo “Executable file $NagiosBin not found. Exiting.”
exit 1
fi
# Check that nagios.cfg exists.
if [ ! -f $NagiosCfgFile ]; then
echo “Configuration file $NagiosCfgFile not found. Exiting.”
exit 1
fi
# See how we were called.
case “$1” in
start)
echo -n “Starting nagios:”
$NagiosBin -v $NagiosCfgFile > /dev/null 2>&1;
if [ $? -eq 0 ]; then
su – $NagiosUser -c “touch $NagiosVarDir/nagios.log $NagiosRetentionFile”
rm -f $NagiosCommandFile
touch $NagiosRunFile
chown $NagiosUser:$NagiosGroup $NagiosRunFile
$NagiosBin -d $NagiosCfgFile
if [ -d $NagiosLockDir ]; then touch $NagiosLockDir/$NagiosLockFile; fi
echo ” done.”
exit 0
else
echo “CONFIG ERROR! Start aborted. Check your Nagios configuration.”
exit 1
fi
;;
stop)
echo -n “Stopping nagios: “
pid_nagios
killproc_nagios nagios
# now we have to wait for nagios to exit and remove its
# own NagiosRunFile, otherwise a following “start” could
# happen, and then the exiting nagios will remove the
# new NagiosRunFile, allowing multiple nagios daemons
# to (sooner or later) run – John Sellens
#echo -n ‘Waiting for nagios to exit .’
for i in 1 2 3 4 5 6 7 8 9 10 ; do
if status_nagios > /dev/null; then
echo -n ‘.’
sleep 1
else
break
fi
done
if status_nagios > /dev/null; then
echo ”
echo ‘Warning – nagios did not exit in a timely manner’
else
echo ‘done.’
fi
rm -f $NagiosStatusFile $NagiosRunFile $NagiosLockDir/$NagiosLockFile $NagiosCommandFile
;;
status)
pid_nagios
printstatus_nagios nagios
;;
checkconfig)
printf “Running configuration check…”
$NagiosBin -v $NagiosCfgFile > /dev/null 2>&1;
if [ $? -eq 0 ]; then
echo ” OK.”
else
echo ” CONFIG ERROR! Check your Nagios configuration.”
exit 1
fi
;;
restart)
printf “Running configuration check…”
$NagiosBin -v $NagiosCfgFile > /dev/null 2>&1;
if [ $? -eq 0 ]; then
echo “done.”
$0 stop
$0 start
else
echo ” CONFIG ERROR! Restart aborted. Check your Nagios configuration.”
exit 1
fi
;;
reload|force-reload)
printf “Running configuration check…”
$NagiosBin -v $NagiosCfgFile > /dev/null 2>&1;
if [ $? -eq 0 ]; then
echo “done.”
if test ! -f $NagiosRunFile; then
$0 start
else
pid_nagios
if status_nagios > /dev/null; then
printf “Reloading nagios configuration…”
killproc_nagios nagios -HUP
echo “done”
else
$0 stop
$0 start
fi
fi
else
echo ” CONFIG ERROR! Reload aborted. Check your Nagios configuration.”
exit 1
fi
;;
*)
echo “Usage: nagios {start|stop|restart|reload|force-reload|status|checkconfig}”
exit 1
;;
esac
# End of this script
7. Далее добавляем Nagios в автостарт и запускаем демона
update-rc.d nagios defaults
service nagios start
8. Настройка веб-сервера Apache
8.1. Создаем пользователя и пароль для веб-интерфейса Nagios:
htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadmin
8.2. Теперь настроим ssl, т. к. использовать незашифрованное соединение – это как-то не спортивно.
Конечно, максимальную защиту даст только сертификат, выданный CA, но он стоит денег (около 99$ в год – зависит от цен конкретной CA), а бесплатно увеличить безопасность – пусть и не идеально – можно и с помощью самоподписанного сертификата. Конечно, при этом вы остаётесь уязвимыми для т. н. man-in-the-middle attack.
Если необходимо, то создать самоподписанный сертификат можно следующим образом:
mkdir /etc/apache2/ssl
cd /etc/apache2/ssl
openssl req -x509 -nodes -days 365 -newkey rsa:4096 -keyout nagios.key -out nagios.crt
Предположим, мы будем использовать дефолтный файл конфигурации apache2 для ssl.
Удаляем конфиг, скопированный при установке, предварительно скопировав его содержимое:
rm /etc/apache2/conf.d/nagios.conf
Редактируем дефолтный конфиг ssl:
nano /etc/apache2/sites-available/default-ssl.conf
Куда помещаем следующее, изменяя на свои значения, если есть различия:
<IfModule mod_ssl.c>
<VirtualHost *:443>
ServerAdmin webmaster@example.com
DocumentRoot /var/www/
ErrorLog ${APACHE_LOG_DIR}/error.log
LogLevel warn
CustomLog ${APACHE_LOG_DIR}/ssl_access.log combined
SSLEngine on
SSLCertificateFile /etc/ssl/certs/ssl-cert-snakeoil.pem
SSLCertificateKeyFile /etc/ssl/private/ssl-cert-snakeoil.key
BrowserMatch “MSIE [2-6]”
nokeepalive ssl-unclean-shutdown
downgrade-1.0 force-response-1.0
BrowserMatch “MSIE [17-9]” ssl-unclean-shutdown
<Directory />
Options -Indexes
</Directory>
ScriptAlias /nagios/cgi-bin “/usr/local/nagios/sbin”
<Directory “/usr/local/nagios/sbin”>
SSLRequireSSL
Options ExecCGI
AllowOverride None
Order allow,deny
Allow from all
# Order deny,allow
# Deny from all
# Allow from 127.0.0.1
AuthName “Nagios Access”
AuthType Basic
AuthUserFile /usr/local/nagios/etc/htpasswd.users
Requir
e valid-user
</Directory>
Alias /nagios “/usr/local/nagios/share”
<Directory “/usr/local/nagios/share”>
SSLRequireSSL
Options None
AllowOverride None
Order allow,deny
Allow from all
# Order deny,allow
# Deny from all
# Allow from 127.0.0.1
AuthName “Nagios Access”
AuthType Basic
AuthUserFile /usr/local/nagios/etc/htpasswd.users
Require valid-user
</Directory>
</VirtualHost>
</IfModule>
Включаем модуль ssl, разрешаем наш ssl-сайт и перезапускаем службу:
a2enmod ssl
a2enmod cgi
a2ensite default-ssl
/etc/init.d/apache2 restart
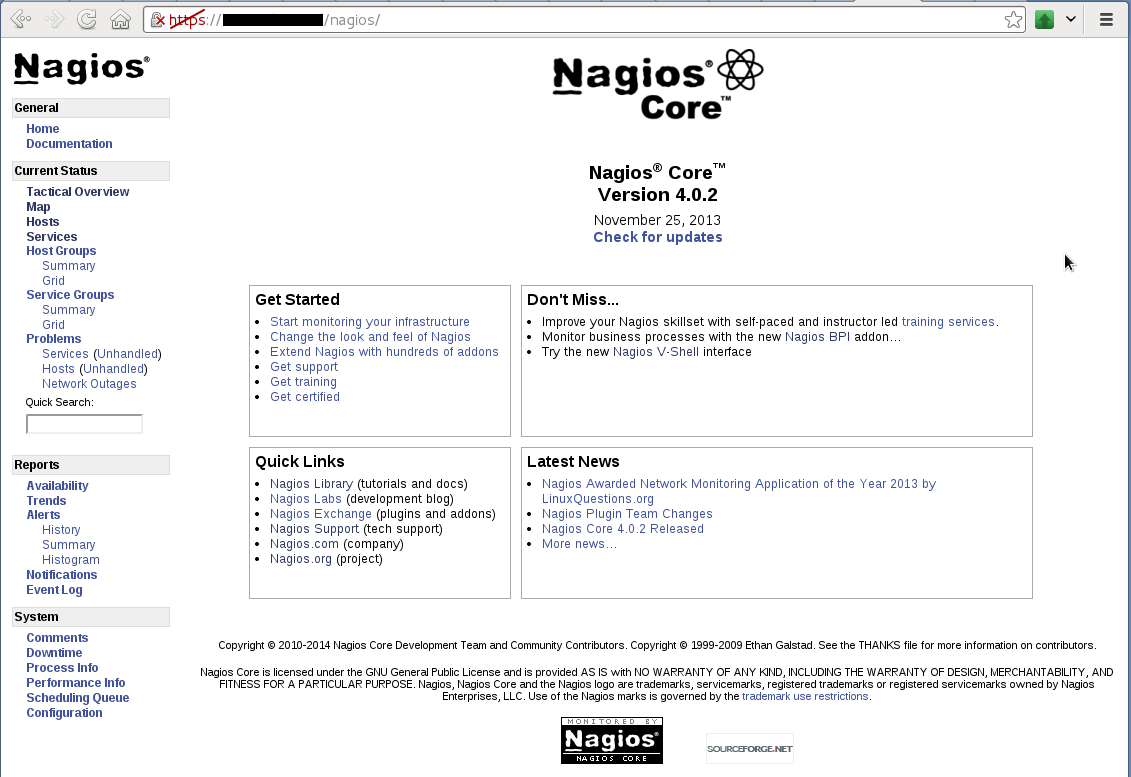
Теперь приверяем. Заходим по адресу https://IP/nagios и после авторизации мы должны увидеть страшный веб-интерфейс Nagios Core:
Также походите по ссылкам в нём, чтобы проверить работоспособность скриптов.
9. Устанавливаем Nagios plugins
cd ../nagios-plugins-1.5-8-g9db76
which openssl
./configure –with-nagios-user=nagios –with-nagios-group=nagios –with-openssl=/usr/bin/openssl –enable-perl-modules –enable-libtap
make
make install
10. Устанавливаем NRPE
cd ../nrpe-2.15
./configure –with-ssl=/usr/bin/openssl –with-ssl-lib=/usr/lib/x86_64-linux-gnu
make
make all
make install
make install-plugin
make install-daemon
make install-daemon-config
cp init-script.debian /etc/init.d/nrpe
chmod 700 /etc/init.d/nrpe
/etc/init.d/nrpe start
Радактируем стартовый скрипт
nano /etc/init.d/nrpe
И для совместимости с Debian добавляем в начало файла:
#!/bin/sh
# Start/stop the nrpe daemon.
#
# Contributed by Andrew Ryder 06-22-02
# Slight mods by Ethan Galstad 07-09-02
### BEGIN INIT INFO
# Provides: nrpe
# Required-Start: $remote_fs $syslog
# Required-Stop: $remote_fs $syslog
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: Start nrpe daemon at boot time
# Description: nrpe daemon 2.15
### END INIT INFO
Включаем в автозапуск:
update-rc.d nrpe defaults
Также не забываем в файл с командами Nagios’a /usr/local/nagios/etc/objects/commands.cfg дописать определение команды для NRPE серверной части:
define command{
command_name check_nrpe
command_line $USER1$/check_nrpe -H $HOSTADDRESS$ -c $ARG1$ -t 30
}
11. Устанавливаем vshell. Не забываем в файле install.php закомментировать строчку для RHEL дистрибутивов:
//define(‘APACHECONF’,”/etc/httpd/conf.d”);
А раскомментировать валидную для Debian:
define(‘APACHECONF’,”/etc/apache2/conf.d”);
Команды:
cd ../vshell
nano install.php
./install.php
Проверяем переходя по ссылке https://IP/vshell.
Далее необходимо приступить к настройке Nagios и серверов, которые планируется мониторить. Но, это уже тема для другой статьи.
Надеюсь – данная будет полезной тем, кто только начал обустраивать свой мониторинг.
Ссылки:
1. Исправлены ошибки в статье.
2. Если возникает ошибка “Starting nagios:No directory, logging in with HOME=/” это значит, что вы не создали домашнюю директорию для пользователя nagios. Делаем: